


#42 Si può correggere Internet?
Cambiare la rappresentazione dei mondi che abitiamo, un clic alla volta.


«Dov’è il potere? Chi ce l’ha? Come sta influenzando la mia vita?», si chiedeva qualche giorno fa
, giornalista e autrice di Dentro l’algoritmo (Effequ, 2022), su Instagram, come corollario a questo suo post:
«Se tutte le polemiche sui Ferragnez a Sanremo fossero di colpo trasformate in proteste e critiche al greenwashing di Eni forse potrei liberarmi dal senso di nausea che provo questa settimana.»
La domanda di Donata mi ha fatto pensare; ho molte idee ma nessuna risposta unica e sviluppabile in un giro di Ojalá. Sono però d’accordo con lei, dovremmo chiederci molto più spesso chi ha il potere e come influenza la nostra vita quotidiana.
Chiediamocelo, e poi portiamo le nostre energie là dove serve che le cose cambino.
Negli ultimi mesi mi sono resa conto che stavo abitando Internet in modo molto distratto. Ho iniziato a notare un malessere fisico, il dito che scrollava e la testa che si barcamenava tra decine di informazioni e video e notizie e meme, tutti in coda per catturare la mia sempre più fievole attenzione, in una gara a chi urla più forte.
Ho sentito che non solo stavo perdendo il controllo della mia attenzione sul web, ma ero sempre più distaccata dal valore umano dei contenuti che stavo fruendo.
Chi si stava prendendo il potere? Io sentivo di non averlo più.
Nel capitolo 5 de Il capitalismo della sorveglianza. Il futuro dell’umanità nell’era dei nuovi poteri (Luiss University Press, 2019), Shoshana Zuboff usa l’esempio di Google come parabola dell’esproprio e della monopolizzazione delle nostre vite:
Le nostre vite offrono nuovo surplus comportamentale ogni volta che hanno a che fare con Google, Facebook e in genere con ogni aspetto dell’architettura informatica di internet. La pervasività globale dei computer è di fatto stata riconfigurata come un’architettura dell’estrazione dal capitalismo della sorveglianza.
[…]
Va bene dare forza alle persone, ma non troppa forza, altrimenti potrebbero accorgersi che il loro diritto di decidere sta venendo rubacchiato, e potrebbero volerlo indietro. L’azienda vuole consentire a tutti di prendere delle decisioni migliori, a patto però che esse non ostacolino gli imperativi di Google. La società ideale per Google è fatta da utenti distanti, e non da cittadini. Idealizza le persone informate, ma solo nei modi decisi dall’azienda. Ci vuole docili, in armonia, e soprattutto riconoscenti.
(pag. 172)
Google e Meta, ovviamente, non sono gli unici attori in questo scenario: possiamo allargare la visione a tutte le realtà imprenditoriali, di qualsiasi settore — intrattenimento incluso —, che monetizzano sui nostri interessi.
Per loro meglio essere docili, in armonia, riconoscenti. Distratti, soprattutto.

Come correggere Internet: un esempio pratico
Pochi giorni dopo aver letto il post di Donata, una persona ha condiviso in uno dei gruppi Slack che frequento il progetto Correct the Internet.
Correct the Internet nasce dalla consapevolezza di un grosso bias nel modo in cui parliamo di sport e record sportivi.
Molte delle persone che hanno collezionato più successi nel mondo dello sport sono donne. Eppure i motori di ricerca che usiamo tutti i giorni hanno imparato dai nostri bias un’altra storia e spesso i loro risultati danno priorità agli atleti uomini. Anche quando i fatti ci dicono che le prime a salire sul podio sono state delle atlete.
Come si fa a correggere internet?
Possiamo imparare a usare in maniera più consapevole la funzione feedback dei motori di ricerca: noi, persone alla tastiera, abbiamo il potere di segnalare le incongruenze che troviamo nei risultati.
Per esempio: qualche mese fa, nel numero 32 di Ojalá, avevo citato un grande bias dietro la notizia della vittoria di Carlos Alcaraz agli US Open: «è il più giovane numero 1 della storia del tennis mondiale», aveva detto la stampa.
Ma non era vero: la più giovane numero 1 è stata Martina Hingis nel 1997.
Le persone che curano Correct the Internet hanno raccolto centinaia di risultati errati che compaiono in primo piano sui motori di ricerca (i cosiddetti snippet di Google) e hanno creato uno strumento per chiederne la correzione in pochi clic.
Se chiediamo in inglese a Google quale tennista ha vinto il maggior numero di titoli di Wimbledon in singolare, la risposta in primo piano è Roger Federer con 8 titoli:
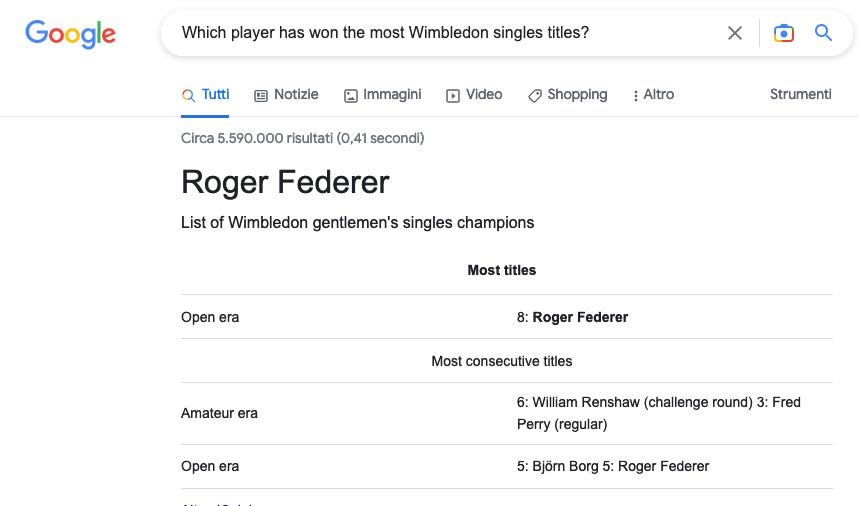
Nonostante la query di ricerca inizi per “which player”, senza alcuna indicazione del genere per il sostantivo player, il risultato dello snippet ci parla di gentlemen, uomini.
Le statistiche ufficiali, invece, danno una risposta diversa alla domanda: il record di titoli Wimbledon in singolare è di Martina Navratilova, che ne ha vinti 9.
Correct the Internet ci invita allora a correggere questa informazione con pochi clic, inviando una nota (già precompilata dal team del progetto, ma modificabile) a Google:

E se facessimo la stessa ricerca in italiano?
Il risultato cambia a seconda di come formuliamo la domanda. Per esempio, provo a digitare lo stesso quesito su Wimbledon usando il sostantivo tennista, che è ambigenere (rimane immutato sia al maschile che al femminile):
Quale tennista ha vinto più Wimbledon?
Google sceglie come snippet da mettere in primo piano il blog di Sisal dove, indovina un po’?, la risposta in grassetto è quella sbagliata:

Per ottenere la risposta giusta, Martina Navratilova, devo chiedere:
Quale tennista donna ha vinto più Wimbledon?

Ora: vedi la voce Feedback, in basso a destra nelle due schermate precedenti? Quando ci fai clic sopra, Google ti chiede cosa pensi dei risultati che ti ha appena mostrato. In questo caso, puoi indicare che il contenuto è fuorviante o impreciso e scrivere perché:

Questo veloce esercizio ci offre l’ennesimo esempio del perché il neutro, in italiano, non esiste. Tennista è un sostantivo ambigenere, eppure Google ci offre risposte che disegnano un mondo a misura d’uomo. E non perché Google ha scelto così, ma perché le sue risposte ricalcano il nostro modo di usare la lingua.
Per iniziare a capire perché questi risultati sono un problema, puoi partire da Dentro l’algoritmo di Donata Columbro. A pagina 105 spiega (il grassetto è mio):
Il linguaggio, nell’evoluzione degli algoritmi, va diventando sempre più centrale: basti pensare all’evoluzione del ‘natural language processing’ che ci permette di digitare non solo parole chiave nei motori di ricerca, ma vere e proprie frasi, domande, che vengono interpretate dal software come se stessimo parlando con una persona in carne e ossa.
[…]
Safiya Umoja Noble, autrice di Algorithms of Oppression, aggiunge altri dettagli al modo in cui il “potere algoritmico plasma la società”. Cercando, per esempio, ‘ragazze nere’ su un motore di ricerca, fino a poco tempo fa emergevano in correlazione termini sessualmente espliciti, mentre digitando ‘ragazze bianche’ i risultati erano radicalmente diversi.
[…] Secondo Noble l’algoritmo non solo riproduce l’oppressione, ma il potere algoritmico è talmente pervasivo che l’utenza interiorizza la rappresentazione che viene fornita online in modo passivo. Perché di un motore di ricerca ci ‘fidiamo’, è il primo che andiamo a consultare per una verifica delle informazioni, senza considerare che invece stiamo usando uno strumento prodotto da un’azienda che genera profitto tramite inserzioni commerciali e non ha alcun interesse a essere un’istituzione pubblica super partes.
Un caso studio e due strumenti che mi sono piaciuti:
Textio ha osservato come certe risposte di ChatGPT siano un ottimo esempio di algoritmi che riproducono l’oppressione: se gli chiedi di scrivere poesie di San Valentino dedicate a gruppi specifici di persone, il risultato è un tripudio di stereotipi sessisti e razzisti.
Ethical Design Guide è una ricca libreria di risorse su come disegnare prodotti etici che non perpetuino pregiudizi: dalle buone norme di accessibilità digitale ai linguaggi inclusivi, c’è davvero un tesoro da scoprire pagina dopo pagina.
Language, Please è una risorsa gratuita e viva dedicata a chi lavora nella comunicazione e vuole esercitarsi a scrivere in modo consapevole di argomenti sociali, culturali e identitari. Dentro ci trovi dei bellissimi esercizi (solo in inglese) per editare testi su macro-temi diversi: classe e posizione sociale; disabilità, neurodivergenze e malattie croniche; genere e sessualità; frontiere e popolazioni; salute mentale, traumi e uso di sostanze; razza sociale e appartenenza etnica.

Prima di chiudere, un grazie speciale alle prime persone che hanno deciso di sostenere Ojalá con il piano premium: 💙

Se vuoi farlo anche tu, puoi creare un account gratuito su Substack (nel caso tu non lo abbia già) e scegliere un piano a pagamento, mensile o annuale, per Ojalá.
Ojalá è gratis e lo rimarrà sempre. Sono gratis anche le condivisioni, i like e i commenti a questo numero della newsletter: piccole azioni che mi regalano tante buenas vibras.
Per questo lunedì ho finito. Se vuoi lasciarmi un'opinione, una richiesta di contenuti futuri o di collaborazione, scrivimi senza problemi.
Ti basta rispondere a questa email.
A presto,
Alice
Hai tradotto in parole quel malessere alla bocca dello stomaco che ho da un po'. E poi lo hai condito di soluzioni, grazie.
Un piacere leggerti